AI workloads break in production, and the evidence of what changed is scattered across every tool you own. Skyportal rebuilds it into one causal timeline — and ships the fix as a PR, proven on staging.
When production breaks today
Something broke in production.No one can say what changed.
The cause could be a deploy, a config value, a model version, or the GPU itself — and the evidence lives in different tools: monitoring, run traces, GitHub, cloud state, deploy history, and Slack.
The slow part isn’t the fix. It’s finding what changed.
EXAMPLE
p95 latency doubled overnight on one inference path. The team tabs between Grafana, MLflow, deploy history, kubectl, and GPU telemetry, rebuilding the timeline by hand. Three hours in — still guessing.
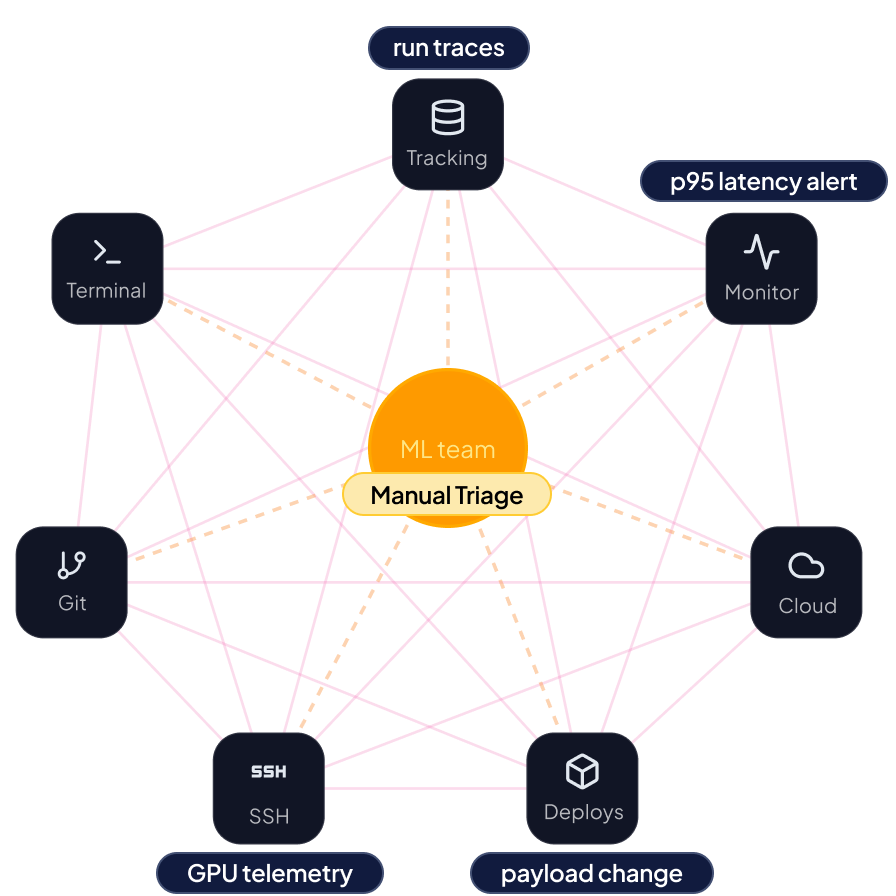
Diagram of a fragmented production-debugging state. Center: ML team performing manual triage. Surrounding: seven disconnected tools (Tracking, Monitor, Cloud, Deploys, SSH, Git, Terminal). Each tool emits an independent signal — run traces from Tracking, p95 latency alert from Monitor, GPU telemetry from SSH, payload change from Deploys. Connections are tangled, illustrating the coordination overhead operators face.
How Skyportal solves it
One timeline. One cause.One fix — proven before prod.
SARA correlates code, configs, model versions, runtime, and GPU telemetry into one causal timeline. She pinpoints what changed, opens the fix as a PR, and proves it on staging — promotion to production stays in your hands.
Days of debugging → minutes to a verified fix.
EXAMPLE
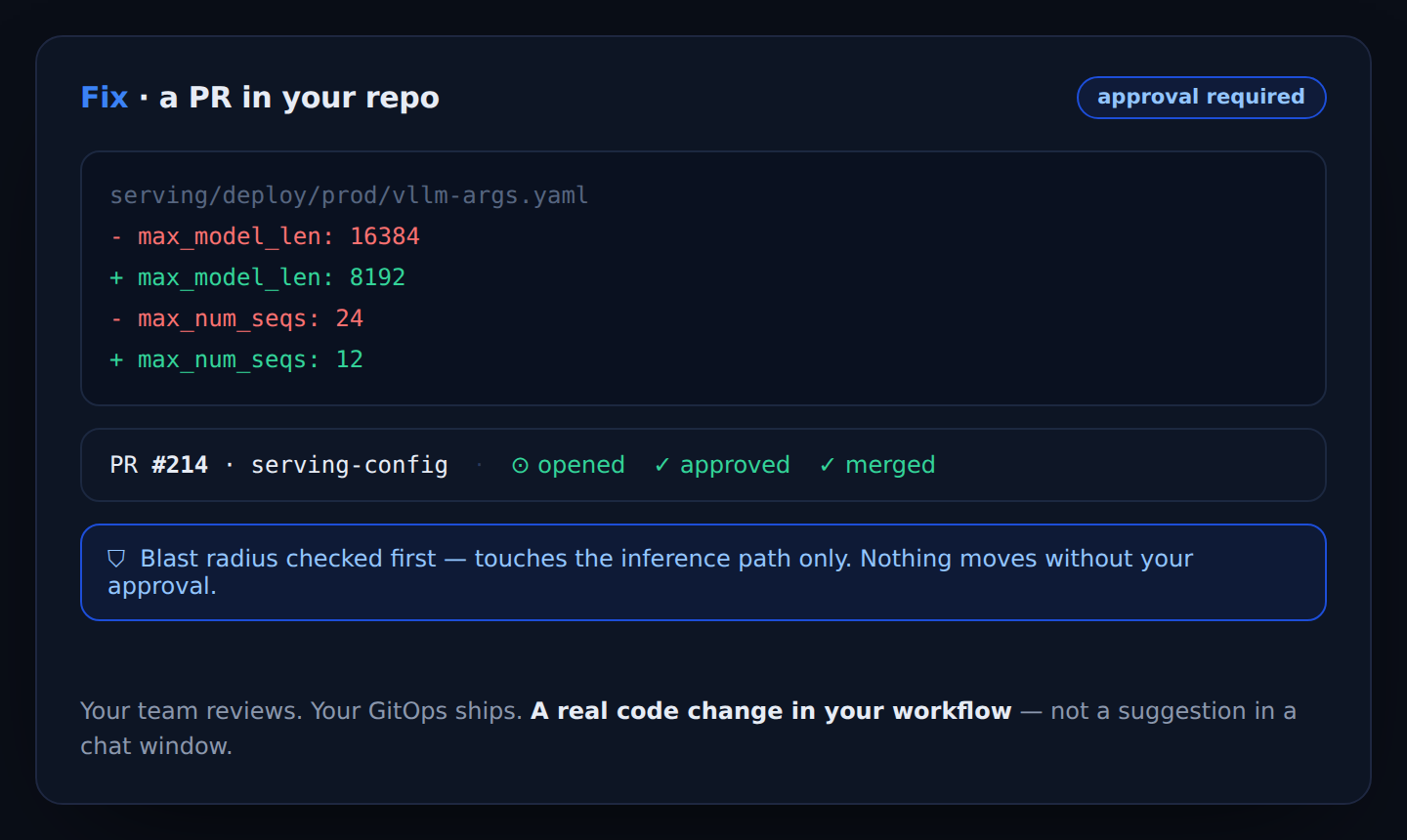
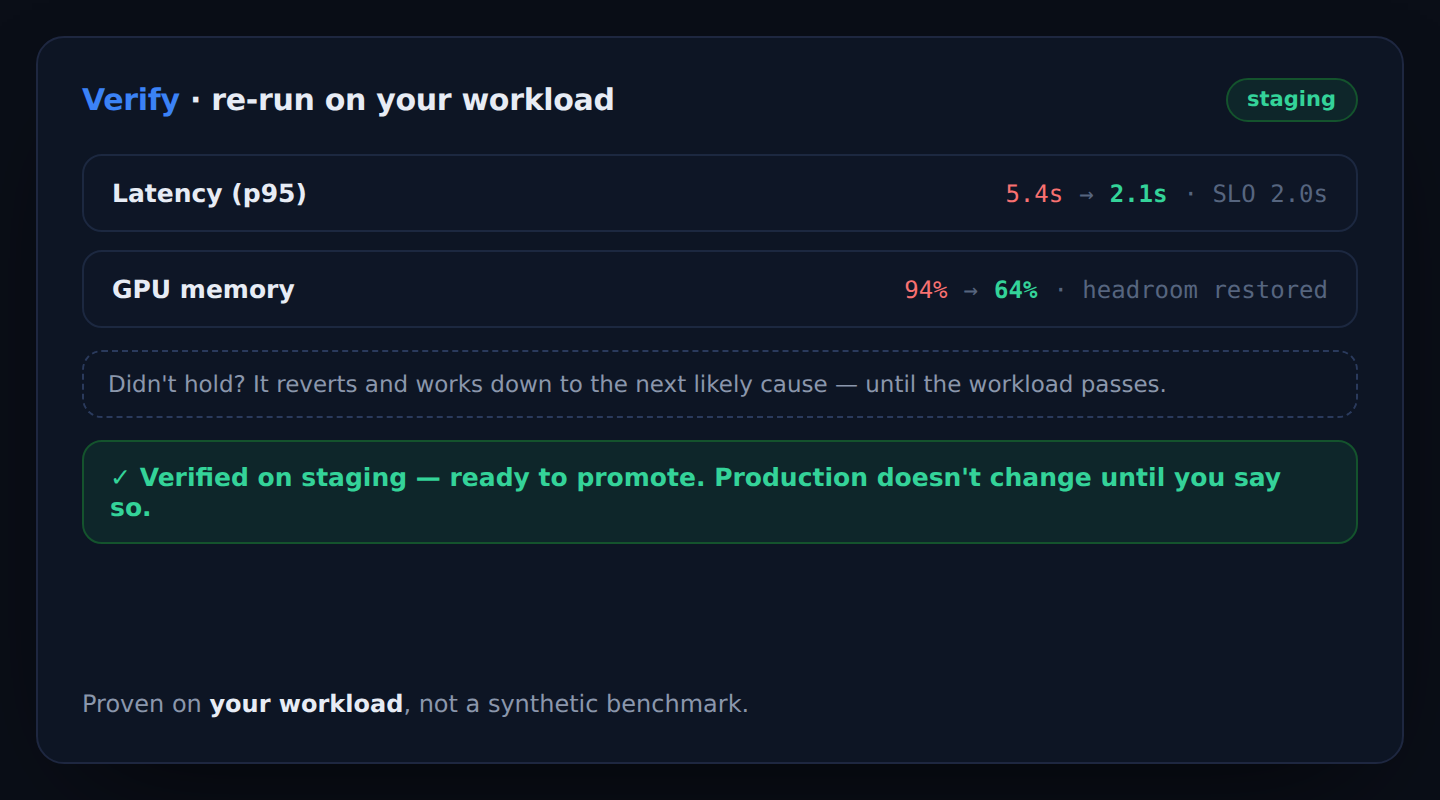
Same incident, with Skyportal: SARA flags last night’s deploy — max_model_len doubled, GPU memory hit 94%. She opens a config PR, re-runs the workload on staging until p95 recovers, and holds for your approval to promote.
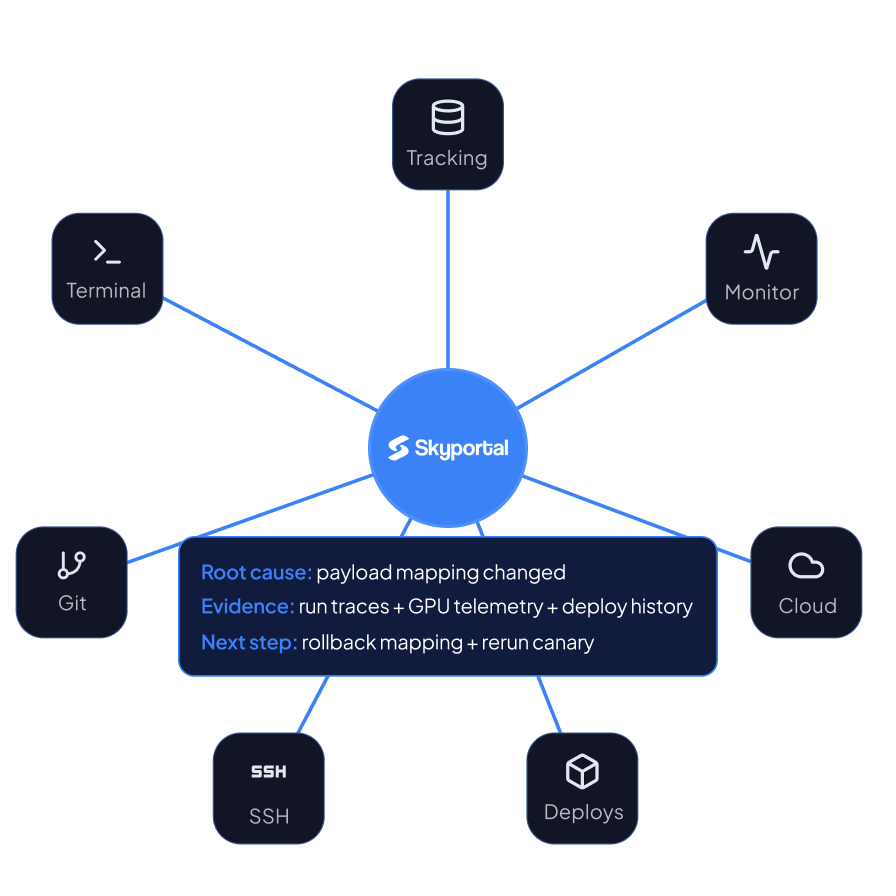
Diagram of Skyportal's unified view. Center: Skyportal connecting all tools through clean hub-and-spoke lines. Overlay near the hub: a Root-cause card from SARA — Root cause: last night's deploy, max_model_len doubled. Evidence: deploy diff plus GPU telemetry plus run traces. Next step: config PR, staging re-run, promote.
Ask SARA what changed — she rebuilds the timeline across code, runtime, models, and infra.
Three common ways production AI breaks.
Every issue is diagnosed in production, every fix is proven on staging, and nothing reaches production until you promote it.
The GPU wasn’t the bottleneck — the CPU control plane was. A config PR, proven on staging: p95 5.1s → 1.8s.
A metric you weren’t tracking — instrumented by SARA in a reviewed PR, ready to promote.
A silent accuracy drop after a data-pipeline change — proven on staging: 0.81 → 0.87.
Spend less time hunting the regression. More time shipping the fix.
Skyportal diagnoses the cause, ships a fix you approve, and proves it on your workload. And because it made that workload production-ready before you shipped, the answer to “what changed” is already there.
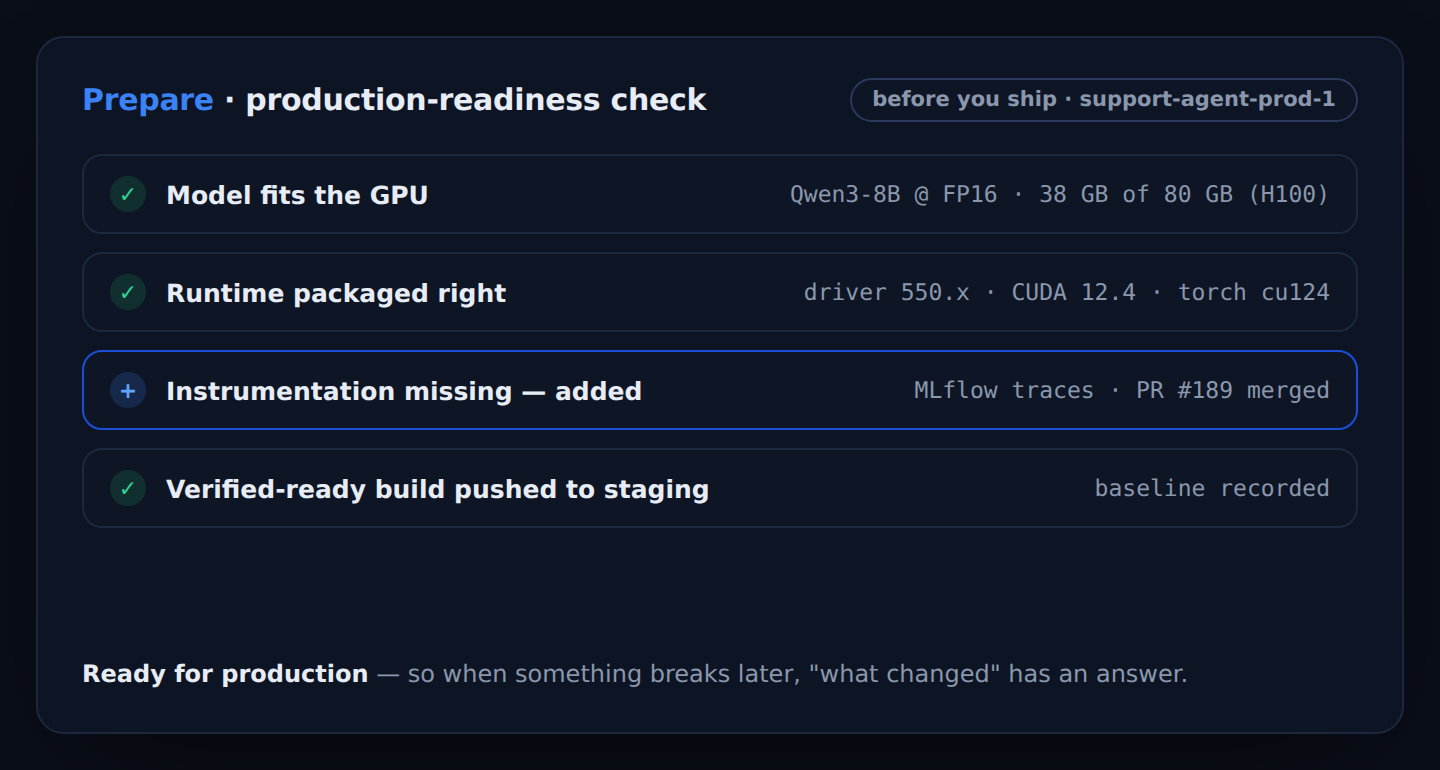
Before you ship, Skyportal checks the workload will actually run — the model fits the GPU, the runtime is packaged right, the instrumentation is in place — and pushes a verified-ready build to staging. So when something breaks later, there’s an answer.
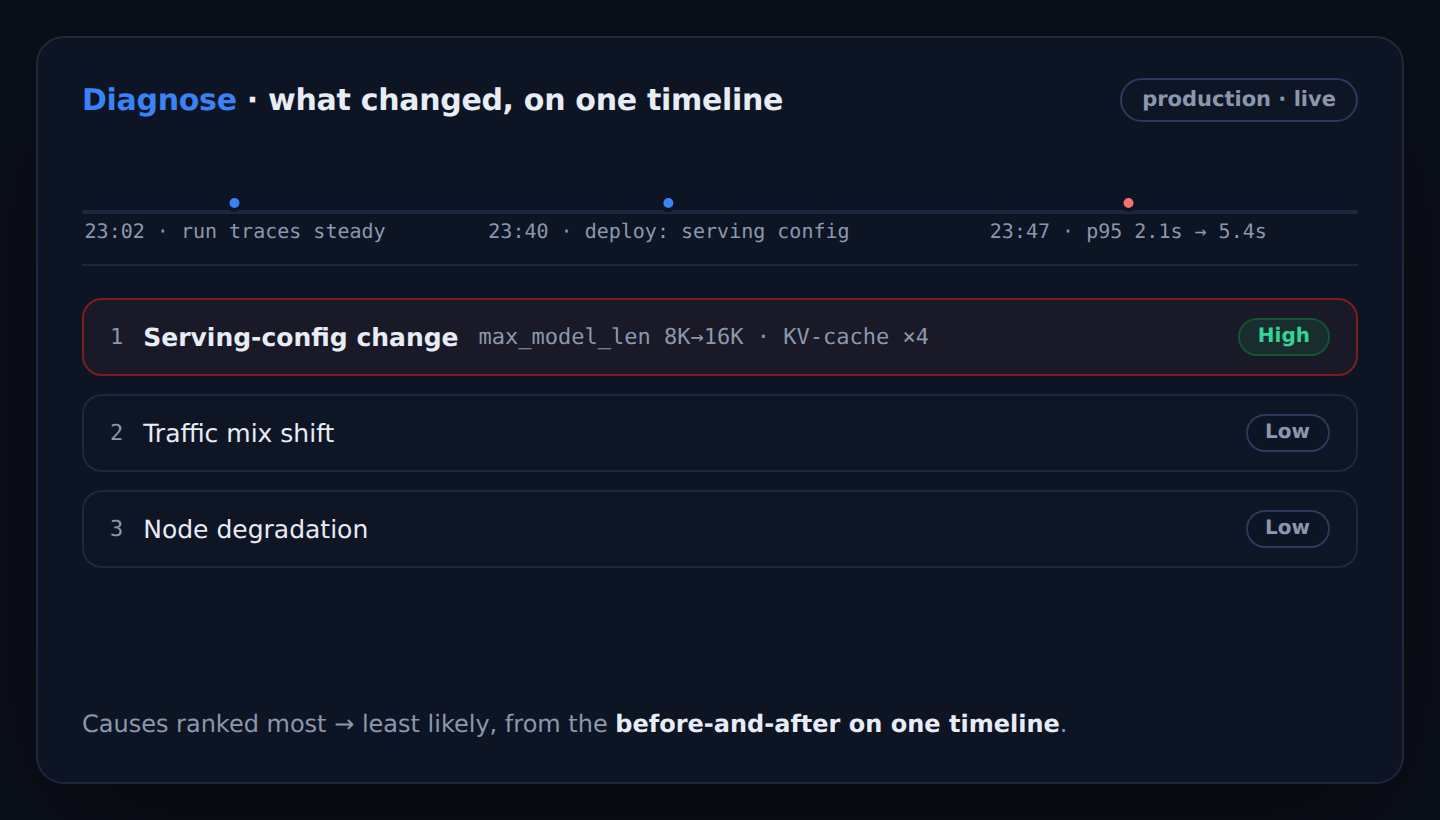
A regression lands, and SARA pulls the before-and-after off one timeline — deploys, configs, model versions, runtime, GPU telemetry — and ranks the likely causes, most to least probable.
It proposes the top fix, checks the blast radius, and — on your approval — opens a pull request in your GitHub. Your team reviews and merges; your GitOps ships it to staging. A real code change in your workflow, not a suggestion in a chat window.
It re-runs your workload on staging to confirm the fix held. If it holds, it’s ready to promote to production; if it doesn’t, it reverts and works down to the next likely cause — until the workload passes.
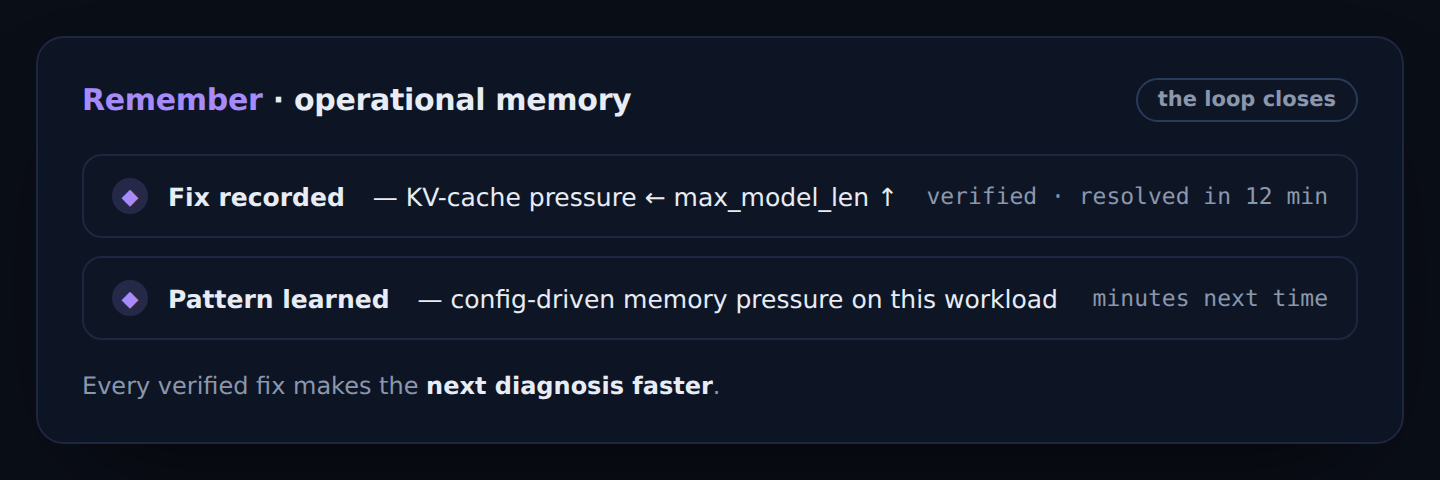
Every verified fix goes into operational memory — so the next diagnosis is faster.
Safe to connect to production.
Read-only first. Nothing changes without your approval. Every change is a reviewable PR; every action is audited.
Read-only first
It watches before it touches anything.
Approval-gated
Changes ship only as PRs you review.
Full audit trail
Every action, logged end to end.
Works with what you already run
No SDK in your serving path. No re-platforming. Skyportal reads from the systems your stack already emits to — and ships changes back through your own GitHub workflow.
Hooks into
Reads state, logs, and run history — and ships changes back as PRs.
Kubernetesstate · deploys · pod logs
Slurmjobs · queues · node state
MLflowruns · metrics · lineage
Weights & Biasesexperiments · metrics
GitHubreads history · opens PRs
Argo / GitHub Actionsyour existing GitOps ships it
GPU & host telemetry
Hardware and host metrics via the standard collectors.
NVIDIA DCGMGPU health · memory · util
Prometheushost & service metrics
OpenTelemetrytraces · logs · metrics
Bring any framework
No per-framework integration or SDK — Skyportal operates at the run, config, and infra layer.
vLLM
TensorRT-LLM
SGLang
PyTorch
XGBoost
+ whatever you run next
Most tools stop at “something’s wrong.” That’s where the hard part starts.
LLM observability watches your app. APM watches your infra. Neither connects the change that broke production — your code, your config, your model version — to the workload it broke. And neither ships a fix and proves it.
Code copilots
Ship code fast. Blind the moment it’s live — no runtime context.
LLM observability
Traces, evals, even auto-fixes. Stops at the app layer — not your config, GPU, or infra.
APM / infra AIOps
Sees clusters, nodes, deploys. Doesn’t touch your code, config, or model lineage — can’t verify the fix.
Every verified fix is remembered. The next diagnosis starts where the last one ended.
Trusted by teams running AI in production
Finding the fix used to take days. Now it takes minutes.
5 minDev → staging
“I didn’t have to wait on an ML engineer.”
— Applied AI Scientist, Series B agent startup · 6-person AI team
10 minPR ready
“It found the missing MLflow metric and synced the PR from the dashboard.”
— ML Platform Engineer, healthcare AI platform · 13 production models
~$7KGPU waste avoided — in a single catch
“It caught the invisible failure before we burned more GPUs.”
— Forward Deployment Engineer, enterprise AI company · 64× H100 fleet
Faster recovery. Lower compute. Engineers back on the roadmap.
Start with one workload.
Priced by workload, not by seat. Every paid tier ships fixes as PRs in your repo, proven on staging — you choose how much Skyportal watches.